注意:笔者经过实验和查阅资料,已在原作基础上做了部分更改。更改不代表原作观点,查看原作请点击下方链接。
原文出处:
作者:
链接:
前言
数据库的查询执行,毋庸置疑是程序员必备技能之一,然而数据库查询执行的过程绚烂多彩,却是很少被人了解,今天哥哥要带你装逼带你飞,深入一下这sql查询的来龙去脉,为查询的性能优化处理打个基础,或许面试你也会遇到,预防不跪还是看看吧。
这篇博客,摒弃查询优化性能,作为其基础,只针对查询流程讲解剖析。
本片博客阐述的过程为
1、上一个标识过的sql语句,展示查询执行的流程
2、上一个流程图
3、做一个例子逐步深入分析,帮助理解
4、做一个装逼的总结
sql查询语句的处理步骤,代码清单
--查询组合字段select (6)distinct (8)top()(5) --连表 (1)from (1-J) join on (1-A) apply as (1-P) pivot ( ) as (1-U) unpivot ( ) as --查询条件 (2)where --分组 (3)group by --分组条件 (4)having --排序 (7)order by
说明:
1、顺序为有1-8,8个大步骤,1-J,1-A,1-P,1-U,为并行次序。如果不够明白,接下来我在来个流程图看看。
2、执行过程中也会相应的产生多个虚拟表(下面会有提到),以配合最终的正确查询。
sql查询语句的处理步骤,流程图
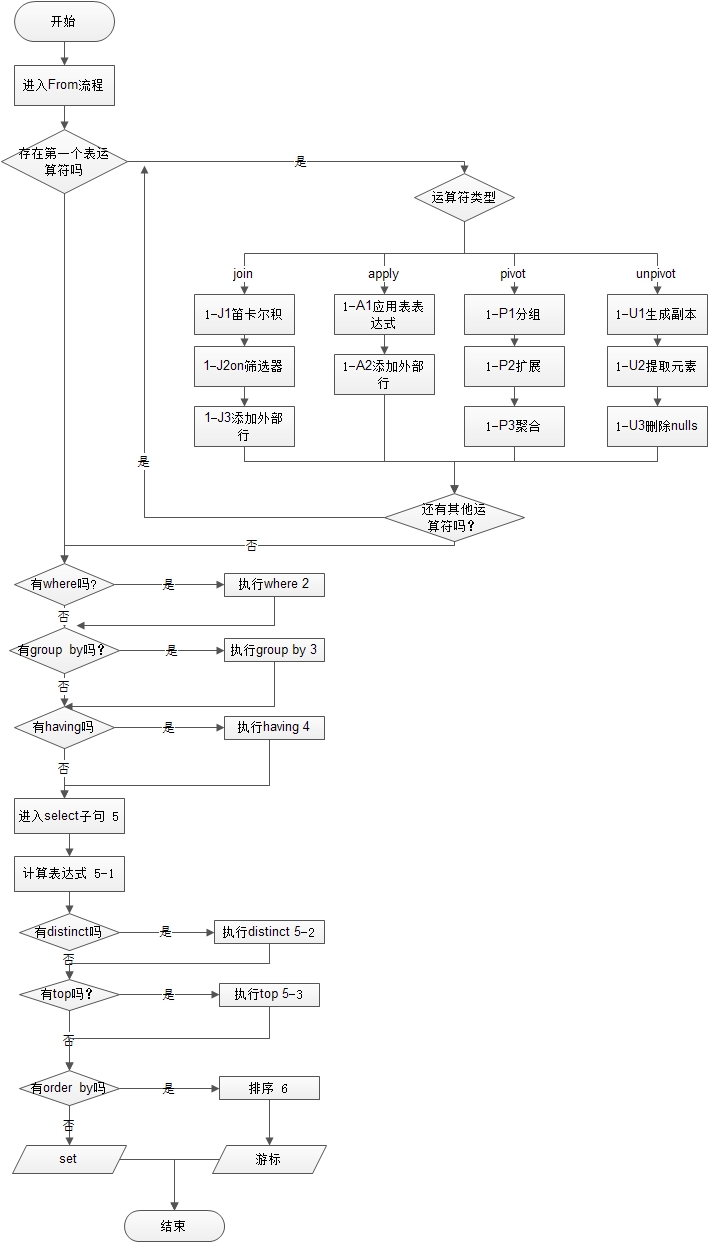
注:上述流程图保留原作。经过实验和查阅资料,做如下修改:计算表达式为第5步,distinct为第6步,order by为第7步,top为第8步,应在order by之后。
实例准备,创建表,插入数据,写要分析的实例查询语句
1、首先创建两个表

2、创建两个表,并插入表数据,脚本如下


USE [test]GO/****** Object: Table [dbo].[Member] Script Date: 2014/12/22 14:05:17 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_PADDING ON GO CREATE TABLE [dbo].[Member]( [id] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](30) NULL, [phone] [varchar](15) NULL, CONSTRAINT [PK_MEMBER] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO SET ANSI_PADDING OFF GO /****** Object: Table [dbo].[Order] Script Date: 2014/12/22 14:05:17 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Order]( [id] [int] IDENTITY(1,1) NOT NULL, [member_id] [int] NULL, [status] [int] NULL, [createTime] [datetime] NULL, CONSTRAINT [PK_ORDER] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO SET IDENTITY_INSERT [dbo].[Member] ON GO INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (1, N'张龙豪', N'18501733702') GO INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (2, N'Jim', N'15039512688') GO INSERT [dbo].[